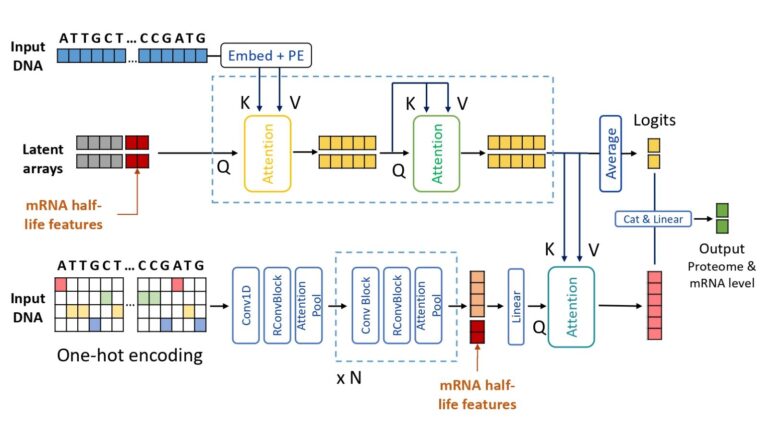
Matteo Stefanini, Marta Lovino, Rita Cucchiara, Elisa Ficarra Journal: Computer Methods and Programs in Biomedicine (CMPB) March 2023 Abstract The functions of an organism and its biological processes result from the ex- pression of genes and proteins. Therefore quantifying and predicting mRNA and protein levels is a crucial aspect of scientific research. Concerning the prediction...
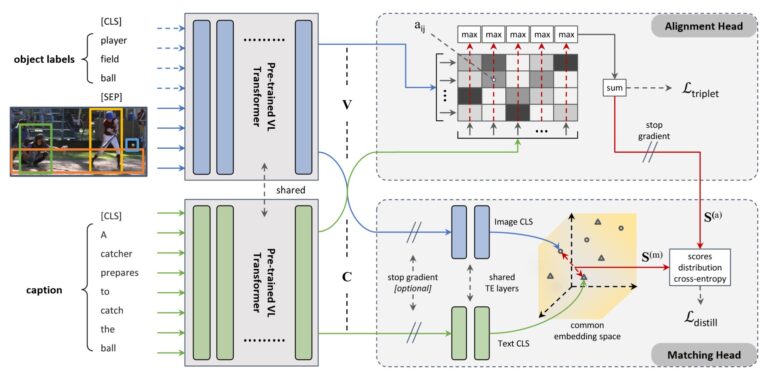
Nicola Messina, Matteo Stefanini, Marcella Cornia, Lorenzo Baraldi, Fabrizio Falchi, Giuseppe Amato, Rita Cucchiara Proceedings of the 19th International Conference on Content-based Multimedia Indexing (CBMI) September 2022 Abstract Image-text matching is gaining a leading role among tasks involving the joint understanding of vision and language. In literature, this task is often used as a...
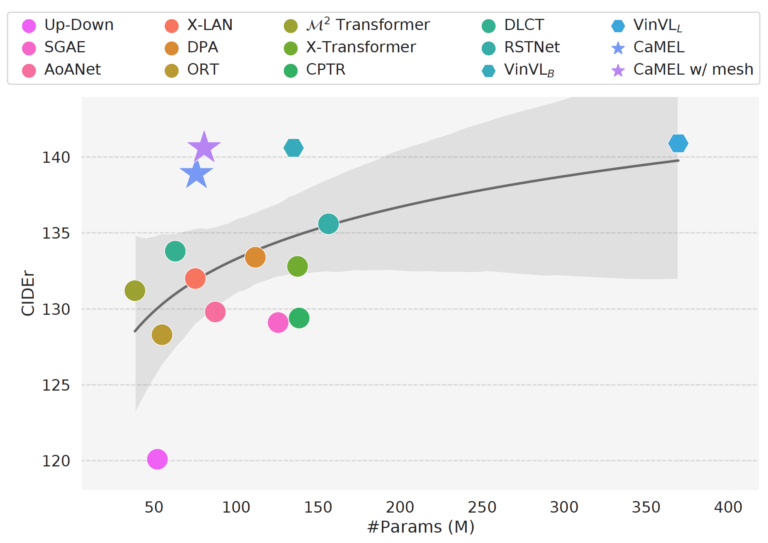
Manuele Barraco, Matteo Stefanini, Marcella Cornia, Silvia Cascianelli, Lorenzo Baraldi, Rita Cucchiara Proceedings of the International Conference on Pattern Recognition (ICPR 2022) April 2022 Abstract Describing images in natural language is a fundamental step towards the automatic modeling of connections between the visual and textual modalities. In this paper we present CaMEL, a novel...
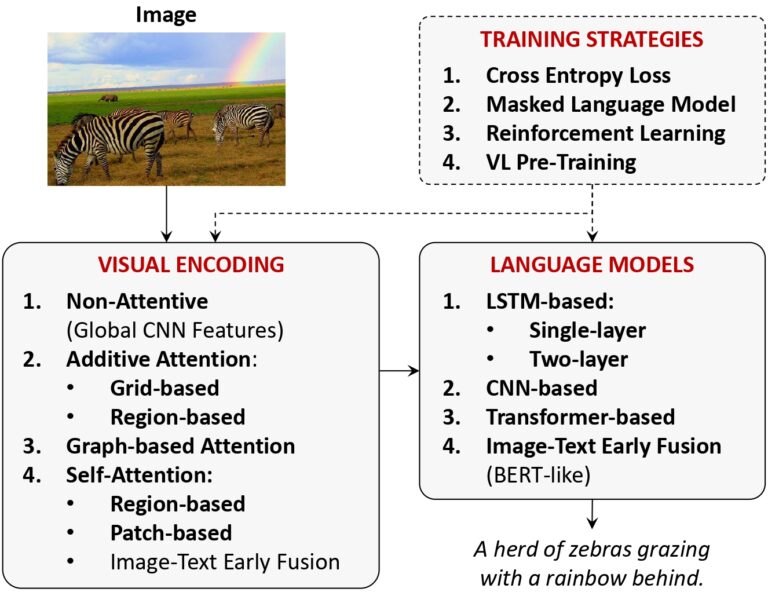
Matteo Stefanini, Marcella Cornia, Lorenzo Baraldi, Silvia Cascianelli, Giuseppe Fiameni, Rita Cucchiara IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) April 2022 Abstract Connecting Vision and Language plays an essential role in Generative Intelligence. For this reason, large research efforts have been devoted to image captioning, i.e. describing images with syntactically...
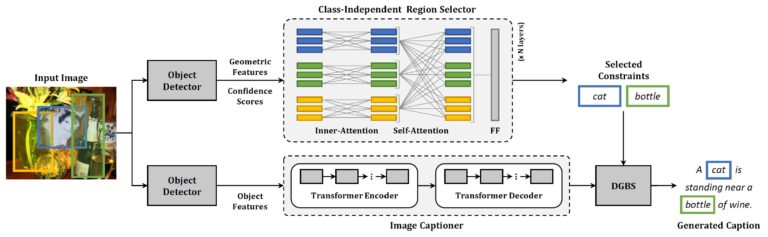
Marco Cagrandi, Marcella Cornia, Matteo Stefanini, Lorenzo Baraldi, Rita Cucchiara Proceedings of the ACM International Conference on Multimedia Retrieval (ICMR 2021) June 2021 Abstract Image captioning models have lately shown impressive results when applied to standard datasets. Switching to real-life scenarios, however, constitutes a challenge due to the larger variety of visual concepts which...
Matteo Stefanini, Marcella Cornia, Lorenzo Baraldi, Rita Cucchiara Proceedings of the International Conference on Pattern Recognition (ICPR 2020) July 2020 Abstract The joint understanding of vision and language has been recently gaining a lot of attention in both the Computer Vision and Natural Language Processing communities, with the emergence of tasks such as image captioning...
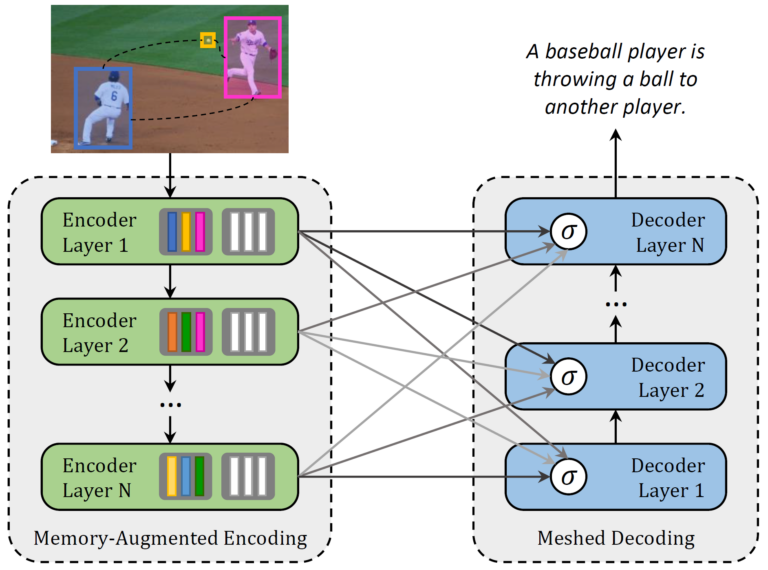
Marcella Cornia, Matteo Stefanini, Lorenzo Baraldi, Rita Cucchiara Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2020) June 2020 Abstract Transformer-based architectures represent the state of the art in sequence modeling tasks like machine translation and language understanding. Their applicability to multi-modal contexts like image captioning, however...
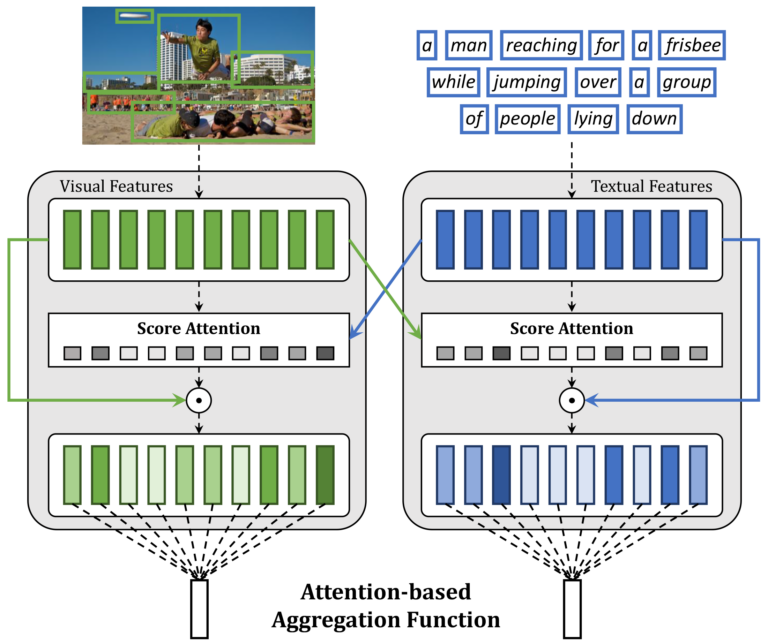
Marcella Cornia, Matteo Stefanini, Lorenzo Baraldi, Massimiliano Corsini, Rita Cucchiara Pattern Recognition Letters September 2019 Abstract Replicating the human ability to connect Vision and Language has recently been gaining a lot of attention in the Computer Vision and the Natural Language Processing communities. This research effort has resulted in algorithms that can retrieve images from...

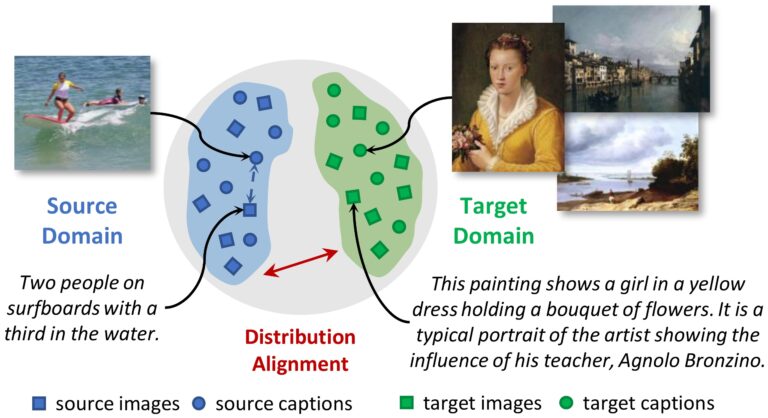
Matteo Stefanini, Marcella Cornia, Lorenzo Baraldi, Massimiliano Corsini, Rita Cucchiara Proceeding of the International Conference on Image Analysis and Processing (ICIAP 2019) June 2019 Abstract As vision and language techniques are widely applied to realistic images, there is a growing interest in designing visual-semantic models suitable for more complex and challenging scenarios. In this...